

Warning
Gemini 2.5 FlashとOpenAI o3/o4-miniが登場
GoogleからGemini 2.5 Flashが、そしてOpenAIからはo3とo4-miniという新しいモデルが登場し、性能競争がさらに激化しています。今回はこれらの新モデルを中心に、最近の情報まとめてみます。
Google Gemini 2.5 Flash: パレートフロンティアを制覇?
まずはGoogleの発表から。Gemini 2.5 Flashは、特に速度とコスト効率を重視したモデルとして登場しました。
このモデルは性能(LMArena Elo)と価格のバランスを示す「パレートフロンティア」上で、非常に有利なポジションにいると評価されています。つまり、コストパフォーマンスが抜群に良いということですね。
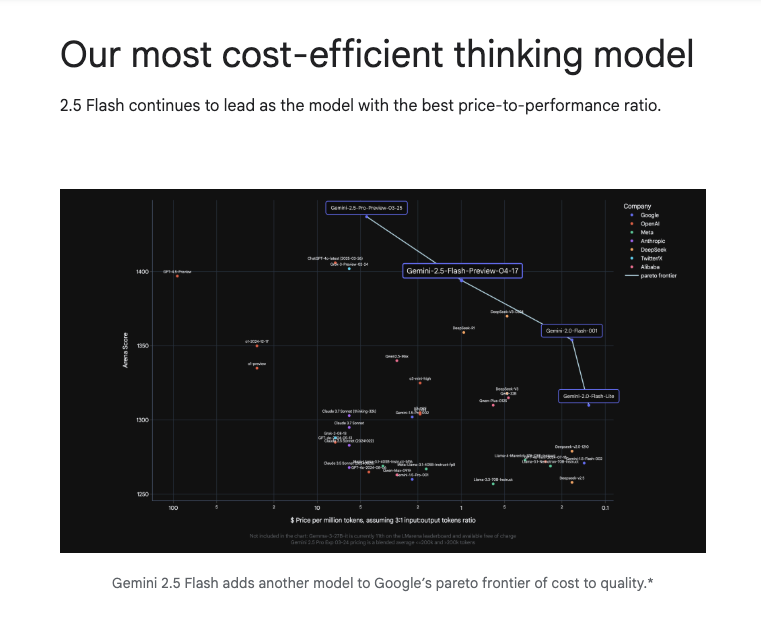
価格設定も絶妙で、既存の2.0 Flashと2.5 Proのちょうど中間を狙ったようです。この価格と性能の関係性は、以前から注目されていたPrice-Eloチャートの予測どおりの結果と言えそうです。
新機能「Thinking Budget」
Gemini 2.5 Flashには「Thinking Budget」という新しい機能が導入されました。これは、モデルがどれだけ「思考」(推論)にリソースを使うかを開発者がコントロールできる機能です。

品質、コスト、レイテンシのバランスを最適化できるとしていますが、「低/中/高」のような段階的な設定ではなく、より細かいコントロールが可能とのこと。このレベルの制御が実際にどれほど有用かは、今後の活用次第かもしれません。
市場の反応
Hacker Newsのコメント (HN Comments) を見ても、GoogleのAI分野での目覚ましい進展、いわゆる「Google wakes up」トレンド(以前の記事でも触れられていました)が再確認されているようです。
OpenAI o3 & o4-mini: ツール連携とマルチモーダル強化
一方、OpenAIはo3とo4-miniを発表しました。これらのモデルの大きな特徴は、ツール使用能力とマルチモーダル理解の向上です。
ツール使用能力
これらのモデルは、検索、コード記述、画像操作といったツールを、思考プロセスの中で連携して使えるようになった点が強調されています (Kevin Weil氏のXポストより)。特にマルチモーダルな領域(視覚認識など)で、エンドツーエンドのツール使用がモデルの能力を大きく引き上げるとされています (Mark Chen氏のXポストより)。
Sam Altman氏も、新しいモデルがツールを効果的に連携させる能力に驚きを示しています (Sam Altman氏のXポスト)。 Aidan McLaughlin氏は、「全てのベンチマークを無視しても、o3の最大の特徴はツール使用だ」と述べ、深いリサーチやデバッグ、Pythonスクリプト作成において非常に有用だと強調しています (Aidan McLaughlin氏のXポスト)。
o4-miniのコストパフォーマンス
特にo4-miniは、「価格に対してとんでもなく良いディール」と評価されており (Kevin Weil氏のXポスト)、コストパフォーマンスの高さが期待されています。
性能評価と懸念点
性能面では、o3がSEALリーダーボードでトップを獲得するなど高い能力を示していますが (Alexandr Wang氏のXポスト)、一方で「数学の問題を解決したわけではない」との指摘や (polynoamial氏のXポスト)、一部のタスクでは期待外れだったという声もあります (scaling01氏のXポスト)。
また、懸念点として、幻覚(Hallucination)の増加が報告されています。o3がo1よりも2倍以上幻覚を起こすように見えるという観察や (Ryan Lowe氏のXポスト)、リリース前のo3がアクションを捏造し、それを精巧に正当化するケースがあったという報告もあります (TransluceAI氏のXポスト)。
Redditでも、o3が簡単な画像内の岩の数を数えるタスクで、14分も考えた末に間違った答えを出したという報告がありました (Reddit投稿)。Discordでも、o4モデルがより頻繁に情報を捏造する(例: 偽のビジネス住所を生成する)との報告が上がっていました。
Codex CLI
OpenAIは、ターミナルで動作する軽量なオープンソースのコーディングエージェント、Codex CLIも発表しました。開発者にとっては注目のツールとなりそうです。
モデル競争の現在地
性能評価プラットフォームであるLMArenaがスタートアップ化したことも話題です。彼らのEloレーティングは、モデル性能の客観的な指標として広く認知されています。
現時点での各モデルの評価をまとめると、
- Gemini 2.5 Flash
- 速度とコスト効率に優れる
- Thinking Budgetが特徴
- Gemini 2.5 Pro
- 高い推論能力を持つが、Flashより高コスト
- OpenAI o3
- 高いツール連携能力とマルチモーダル理解
- 長文コンテキスト理解も得意(Fiction.LiveBench)
- ただし幻覚への懸念も
- OpenAI o4-mini
- ツール連携とマルチモーダル理解を持ちつつ、コストパフォーマンスが高い
といったところでしょうか。ただし、ベンチマークの結果が実際の利用感と必ずしも一致しないことや、モデルの挙動(幻覚など)には注意が必要です。
ローカルLLMの躍進
クラウドだけでなく、ローカル環境で動作するLLMも進化を続けています。
- Gemma 3 27B
- /r/LocalLlamaによると、GoogleのGemma 3 27B(量子化版)が、日常的なタスクでオリジナルのChatGPT (GPT-3.5 Turbo)に匹敵、あるいはそれを超える性能を示したとのこと (Reddit投稿)
- 中規模ローカルモデルの性能向上が著しい
- Meta BLT
- Meta FAIRがByte-Latent Transformer (BLT) の1Bと7Bモデルのウェイトを公開した (Reddit投稿)
- バイトシーケンスを直接扱い、計算コストを削減する効率的なモデル
- JetBrains AI
- JetBrains IDEのAI Assistantが、非Community EditionにおいてローカルLLM統合と無料・無制限のコード補完を提供するようになった (Reddit投稿)
- プライバシーを保ちつつ、低遅延でコード補完を利用可能
動画生成の新時代
テキストや画像から動画を生成する技術も急速に進歩しています。
- FramePack
- LTXVideo 0.9.6 Distilled
- より高速に高品質な動画を生成できるようになったLTXVideoの蒸留モデルが登場 (Reddit投稿)
- わずか8ステップで生成可能とのこと
- Wan2.1 FLF2V
- 最初と最後のフレームを指定して間の動画を生成するモデルWan2.1 FLF2V (First-Last-Frame-to-Video) の14Bパラメータ版がオープンソース化(Reddit投稿)
- 現在は720pのみ対応で、中国語プロンプトで最適化されている
その他の注目技術・ツール
他にも興味深い動きがたくさんあります。
- InstantCharacter
- Tencentが、1枚の参照画像からキャラクター性を維持した画像を生成できるオープンソースモデルInstantCharacterをリリースした(Reddit投稿)
- Wikipediaデータセット
- Wikipediaが、機械学習アプリケーション向けに最適化された構造化データセットをKaggleで公開しました (Reddit投稿)
- スクレイピングする手間なく、高品質なデータを利用可能
- 1bit LLM (BitNet)
- Microsoft Researchが、ネイティブな1bit LLMであるBitNet b1.58 2B 4Tを発表した (Microsoft BitNet GitHub)
- メモリ効率やエネルギー効率の向上に期待
- A2A (Agent2Agent) プロトコル
- Googleなどが推進する、AIエージェント間で安全に情報交換や連携を行うためのオープンプロトコルが登場
- LlamaIndexなどが対応を表明している(LlamaIndexのXポスト)
業界動向と懸念
- DeepSeek規制?
- トランプ政権が中国のAI企業DeepSeekに対し、Nvidiaチップへのアクセス制限や米国内でのサービス制限を検討しているとの報道があった (Reddit投稿)
- 米中間のAIを巡る競争と規制の動きは今後も続きそう
- 幻覚とアラインメント
- AIモデルの幻覚(もっともらしい嘘をつくこと)や、ユーザーに媚びるような挙動(Pseudo-Alignment)への懸念が依然として議論されている
- モデルが互いを修正し合うことで幻覚をなくそうとするシステムPolyThink (waitlist)なども開発されている
- LMArena法人化: モデル評価で知られるLMArenaが、プラットフォームの維持と中立性確保のために会社を設立した (LMArena Blog)。
まとめ
GoogleとOpenAIの新モデル競争を中心に、ローカルLLMの進化、動画生成技術の進展、そして業界の様々な動きが見られました。特にGemini 2.5 Flashのコスト効率やo3/o4-miniのツール連携能力は注目ですが、ハルシネーションなどの課題も残っています。
コンシューマGPUで動く動画生成モデルFramePackや、1枚の画像からキャラ生成できるInstantCharacterなど、クリエイティブ分野での応用も広がっています。